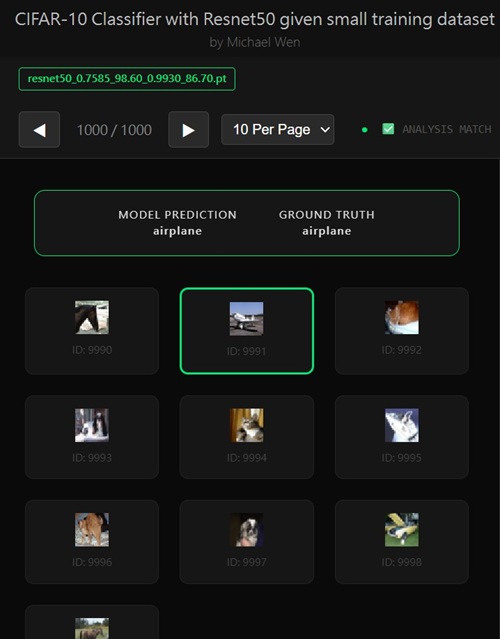
Michael's classification ResNet model using transfer learning and CIFAR-10 dataset
Note: I wrote an app to classify an object using transfer learning, and the model was trained on CIFAR-10 dataset, all by myself.Here's the app:
Motivation - Use Transfer Learning and Low Sample Size for Training
At the very beginning of this project, the motivation was pretty straightforward but also very grounded in real-world constraints. I had learned about transfer learning conceptually, but I didn’t want it to stay as theory—I wanted to actually stress-test it in a scenario that felt realistic.In many production or applied settings, you don’t get the luxury of massive, perfectly labeled datasets. Often you’re dealing with limited samples, either because data is expensive to collect, difficult to label, or simply doesn’t exist in large quantities yet.
Constraint - Low Sample Size for Training
So I set a very concrete goal for myself: train a high-performing image classification model using transfer learning while limiting the training data to just 100 samples per class.That constraint wasn’t accidental—it was the core of the experiment. If transfer learning couldn’t work well under those conditions, then it wouldn’t be nearly as useful as it’s often advertised.
MobileNet V2, MobileNet V3, ResNet-18, and ResNet-34
Once that constraint was in place, the next challenge was deciding which pretrained models were actually worth trying. The ecosystem of foundation models is huge, and it’s easy to get distracted or over-engineer things by testing everything under the sun.Instead, I did some focused research and narrowed the list down to four models that struck a good balance between practicality, maturity, and prior success on vision tasks: MobileNet V2, MobileNet V3, ResNet-18, and ResNet-34. These models are widely used, well-documented, and pretrained on large-scale datasets, which makes them strong candidates for transfer learning.
MobileNet variants are especially appealing because they’re lightweight and efficient, while the ResNet family is known for its stability and strong representational power even at relatively shallow depths.
Conclusion & Findings
After running experiments and comparing results, an interesting pattern started to emerge. While the MobileNet models performed reasonably well—especially considering their efficiency—the ResNet models consistently delivered better validation accuracy under the same low-data conditions.This wasn’t something I assumed going in; it was something that became clear empirically. ResNet-18 and ResNet-34 seemed to extract more robust and transferable features that held up better when fine-tuned with only 100 samples per class. In other words, when data was scarce, the extra representational strength of ResNet mattered more than the efficiency advantages of MobileNet.
That realization became an early but important lesson in the project: theoretical appeal and real-world performance don’t always line up, and careful experimentation is what ultimately guides good architectural choices.
What's next?
The next question, naturally, was how to actually train the model in a way that respected all of those constraints while still delivering strong results. If you take the most straightforward approach—load a pretrained model, replace the classifier head, fine-tune everything end to end with only 100 samples per class—you quickly run into a hard ceiling. In my early attempts, validation accuracy would stall somewhere around 60% to 70%, no matter which backbone I used. At that point it became clear that transfer learning alone, applied naïvely, wasn’t enough. The small-data regime changes the rules, and without additional care the model simply doesn’t have enough signal to generalize well.What followed was a much deeper, more iterative process than I originally anticipated. Pushing validation accuracy toward 90% required a series of deliberate choices, refinements, and empirical lessons learned along the way. There wasn’t a single “magic trick” that made the difference; instead, it was the accumulation of many small but critical decisions—how and when to fine-tune, how to manage overfitting, how to structure the training stages, and how to make the most of every limited sample available. Each adjustment nudged the model a little further, and over time those incremental gains compounded into something substantial.
All of this experimentation was done using the CIFAR-10 dataset, which turned out to be an excellent testbed for this kind of work. On the surface, CIFAR-10 looks simple: small images, only ten classes, and a dataset that’s widely used in tutorials. But under strict data constraints, it becomes surprisingly challenging. That combination made it perfect for exploring what transfer learning can really achieve when resources are limited. The journey from a seemingly stuck 60–70% validation accuracy to a model approaching 90% wasn’t quick or obvious, but it was precisely that gap that made the process interesting—and worth documenting. What follows is a breakdown of the techniques, insights, and lessons that ultimately made that jump possible.
Any comments? Feel free to participate below in the Facebook comment section.