Three-Stage Fine-Tuning
I wrote an app to classify an object using transfer learning, and the model was trained on CIFAR-10 dataset, all by myself.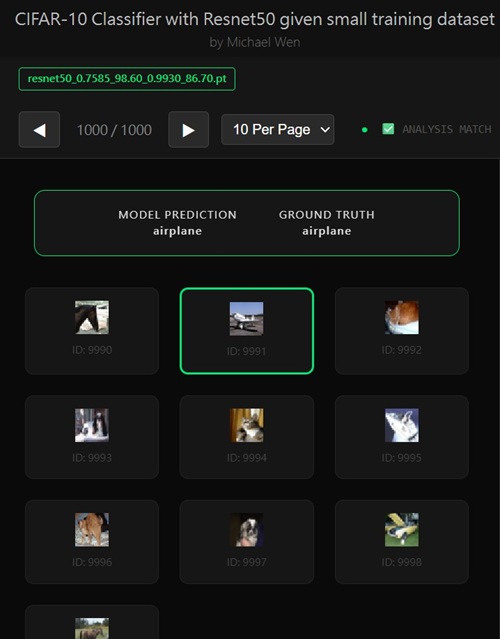
Exploring Stage-3 Fine-Tuning: How Far Should We Unfreeze?
Why Consider a Third Fine-Tuning Stage?
After validating that two-stage fine-tuning produces consistent and reproducible gains, the next natural question is not “what else can we add?” but rather: “Can the data support releasing even more capacity?” This distinction matters. Stage-3 fine-tuning is not an automatic upgrade — it is a hypothesis that must be justified by learning dynamics and validated empirically.Proposed Three-Stage Fine-Tuning Schedule
Stage Definitions
- Stage 1: Train
fconly - Stage 2: Unfreeze
layer4+fc - Stage 3: Unfreeze
layer3+layer4+fc
What Each Stage Is Responsible For
Stage 1: Linear Readout Alignment
At this stage, the pretrained backbone is fully frozen. The model learns:- How to map existing high-level features to new class labels
- Initial decision boundaries without modifying representations
- A stable baseline for downstream adaptation
Stage 2: High-Level Semantic Adaptation
Unfreezinglayer4 enables:
- Task-specific refinement of semantic features
- Better alignment between logits and class structure
- Correction of ImageNet-specific biases
Stage 3: Mid-Level Representation Adjustment
Unfreezinglayer3 allows the network to modify:
- Object parts and spatial configurations
- Mid-level texture and shape cues
- Feature compositions that feed into high-level semantics
Why Stage-3 Fine-Tuning Is Risky on Small Datasets
Unfreezinglayer3 introduces a large number of trainable parameters.
On a limited dataset, this creates several risks:
- Representation drift: pretrained features may be overwritten
- Overfitting: mid-level features adapt too closely to training samples
- Optimization instability: gradients propagate deeper into the network
When Stage-3 Fine-Tuning Makes Sense
Despite the risks, there are scenarios where Stage-3 can help:- The target dataset is visually very different from ImageNet
- Classes depend on subtle part-level differences
- Strong regularization and low learning rates are in place
How Stage-3 Fits Into a Data-Driven Workflow
The key point is that Stage-3 is not attempted blindly. Before introducing it, the data already told us:- Optimization had stabilized
- Two-stage tuning produced consistent gains
- Validation accuracy had not saturated dramatically
Expected Outcomes and Diagnostic Signals
Positive Signals
- Validation accuracy increases beyond two-stage results
- Validation loss decreases or remains stable
- Training accuracy does not spike too early
Negative Signals
- Training accuracy quickly returns to 100%
- Validation loss increases
- Validation accuracy becomes unstable across runs
Why This Experiment Matters Even If It Fails
Whether Stage-3 improves performance or not, the experiment is valuable.- If it works, we learn that mid-level features matter for this task
- If it fails, we confirm that higher-level adaptation is sufficient
Key Takeaway
Stage-3 fine-tuning is about asking a precise question: “Does my data justify changing how the network sees parts and structures?” By progressing one stage at a time and letting validation metrics guide decisions, we ensure that every increase in model freedom is earned — not assumed.My Two-Stage Training Results
Stage-1 Best results: Train Loss: 1.1005 | Val Loss: 1.3094 | Train Acc: 85.70% | Val Acc: 72.50%Stage-2 Best results: Train Loss: 0.7060 | Val Loss: 1.0932 | Train Acc: 100.00% | Val Acc: 86.20%
So in short, my stage-2 result already says “layer4 works”. I hit:
100% train acc
86.2% val acc
That means:
layer4 + fc already fully adapted; the remaining gap is earlier feature abstraction.
What the Two-Stage Results Tell Us Before Attempting Stage-3
Before introducing a third fine-tuning stage, it is critical to pause and interpret the best results from Stage-1 and Stage-2. These numbers are not just checkpoints — they describe how learning capacity is being absorbed by the model.Stage-1 Outcome: Feature Space Is Already Highly Informative
Stage-1 training (fc only) achieved:Train Acc: 85.70% | Val Acc: 72.50%This is an unusually strong result for a frozen backbone. It tells us that:
- The ImageNet-pretrained ResNet-18 features are already well-aligned with CIFAR-10
- Class separation exists even without any backbone adaptation
- The task does not fundamentally require redefining mid-level representations
Stage-2 Outcome: Most Transfer Learning Gains Are Already Captured
After unfreezinglayer4, Stage-2 reached:
Train Acc: 100.00% | Val Acc: 86.20%The jump from 72.5% → 86.2% confirms that high-level semantic adaptation was both necessary and effective. However, the accompanying signals matter just as much:
- Training accuracy saturates completely
- Validation loss remains relatively high
- The train–validation gap widens again
Implication for Stage-3 Fine-Tuning
Taken together, these two stages strongly suggest that:- The dataset benefits from high-level adaptation (Stage-2)
- Mid-level features are already sufficiently expressive
- Additional capacity is more likely to increase variance than reduce bias
layer3 introduces a large number of parameters precisely when the model is
already memorizing the training set.
Data-Driven Expectation for Stage-3
Based on these results, a realistic expectation for Stage-3 would be:- Training accuracy remains at or near 100%
- Validation loss increases or becomes unstable
- Validation accuracy fluctuates or declines across runs
Conclusion: Why This Analysis Matters
The decision to attempt or skip Stage-3 is no longer subjective. The data already provides a strong prior: Two-stage fine-tuning captured the majority of transferable signal, and the remaining error is more likely due to data limitations than representational limits. This is exactly the kind of evidence-based reasoning that prevents overfitting-driven regressions and keeps the optimization process principled.Any comments? Feel free to participate below in the Facebook comment section.