Data Augmentation Pipeline
I wrote an app to classify an object using transfer learning, and the model was trained on CIFAR-10 dataset, all by myself.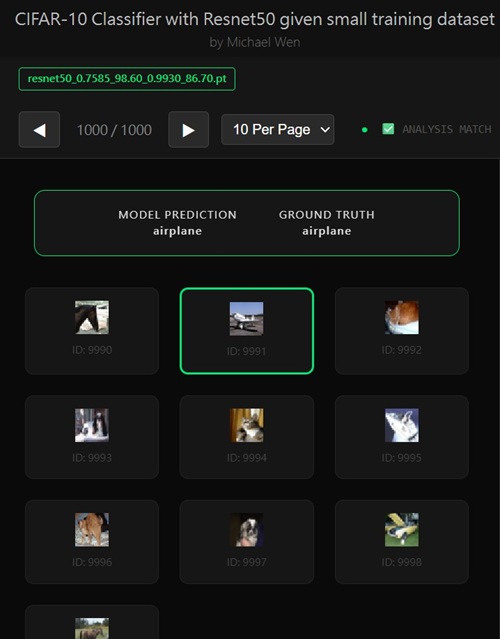
Data Augmentation Pipeline
To combat the brutally low sample size, the first thing I had to address was the most obvious bottleneck: data volume. If I couldn’t realistically collect more images, then the only option was to manufacture diversity from what I already had. That’s where data augmentation became absolutely critical.Instead of treating the 100 samples per class as fixed and immutable, I leaned heavily on a fairly aggressive—but still semantically safe—augmentation pipeline. During training, each image was randomly transformed on the fly using a combination of spatial and photometric operations. This included random cropping with padding to simulate slight shifts and framing errors, horizontal flips to account for viewpoint symmetry, and mild rotations to improve robustness to small orientation changes. On top of that, color-based augmentations such as brightness, contrast, and saturation jitter were applied to prevent the model from overfitting to very specific lighting conditions or color distributions. All images were then normalized using standard CIFAR-10 statistics to keep the input distribution aligned with what the pretrained backbones expect.
What made this especially powerful is that these transformations were stochastic and applied every single time an image was seen during training. In practice, the model almost never encountered the exact same image twice. Over the course of training, those original 100 samples per class effectively expanded into thousands of distinct variations, each preserving the original label while forcing the network to focus on more general, invariant features rather than memorizing pixel-level details. With such a small dataset, this distinction mattered enormously. Without augmentation, the model would latch onto superficial cues and overfit almost immediately; with augmentation, training became both more stable and far more meaningful.
Empirically, the impact was hard to miss. Before introducing this augmentation strategy, validation accuracy would reliably plateau somewhere in the 65–80% range, regardless of which backbone I used. Once the full augmentation pipeline was in place, validation accuracy jumped by roughly 3%, even before any more advanced techniques were applied. That single improvement turned an underwhelming baseline into something genuinely promising.
In hindsight, data augmentation wasn’t just a supporting trick in this project—it was the foundation that made everything else possible. It created the conditions under which transfer learning could actually shine in a low-data regime, and it set the stage for the more nuanced training strategies that followed.
All of this experimentation was done using the CIFAR-10 dataset, which turned out to be an excellent testbed for this kind of work.
Any comments? Feel free to participate below in the Facebook comment section.