Two-Stage Fine-Tuning For Transfer Learning With Resnet-18
I wrote an app to classify an object using transfer learning, and the model was trained on CIFAR-10 dataset, all by myself.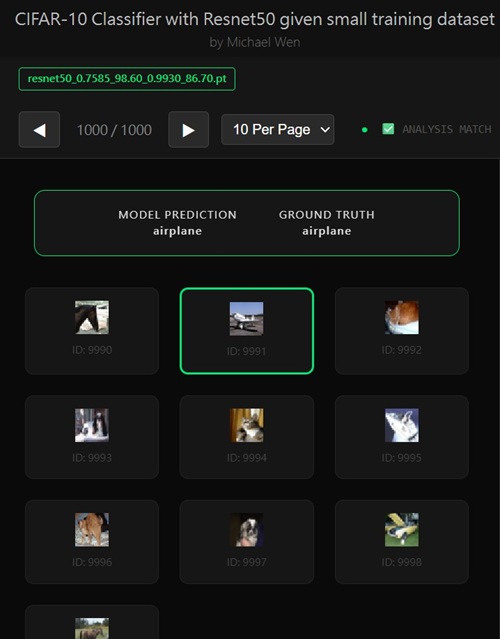
Two-Stage Fine-Tuning for Transfer Learning with ResNet-18
What Is Two-Stage Fine-Tuning?
Two-stage fine-tuning is a structured approach to adapting a pretrained model to a new task. Instead of unfreezing all layers at once, we fine-tune the network in stages, starting from the top (task-specific layers) and gradually moving deeper into the backbone.For a
ResNet-18 pretrained on ImageNet, this method works especially
well because different layers learn features of different abstraction levels.
Why Fine-Tuning in Stages Matters
If all layers are unfrozen immediately:- Gradients from a small dataset can overwrite pretrained features
- Training becomes unstable
- Validation accuracy may stagnate or degrade
ResNet-18 Layer Hierarchy
Conceptually, ResNet-18 can be divided into:- Early layers:
conv1,layer1→ edges, textures - Middle layers:
layer2,layer3→ shapes, parts - Late layers:
layer4,fc→ semantics, classes
Stage 1: Fine-Tune the Head and Top Layers
Objective
Adapt the pretrained model to the new dataset while preserving general visual features learned from ImageNet.Layers to Unfreeze
In Stage 1, we typically unfreeze:fc(classification head)layer4(highest residual block)
Why This Works
The classifier head is randomly initialized and must be trained from scratch.layer4 already contains high-level semantic features that can be safely
adapted without destabilizing the network.
Example: Freezing and Unfreezing Layers
# Freeze all parameters
for name, param in model.named_parameters():
param.requires_grad = False
# Unfreeze layer4
for name, param in model.layer4.named_parameters():
param.requires_grad = True
# Unfreeze fully connected layer
for name, param in model.fc.named_parameters():
param.requires_grad = True
Typical Training Behavior
- Rapid improvement in validation accuracy
- Stable loss curves
- Minimal overfitting early on
Stage 2: Fine-Tune Mid-Level Features
Objective
Refine feature representations by allowing limited adaptation of deeper layers without damaging low-level visual primitives.Layers to Unfreeze
In Stage 2, we commonly unfreeze:layer3
layer1, layer2) usually remain frozen for
small datasets.
Why Not Unfreeze Everything?
Lower layers encode universal features like edges and color contrasts. Updating them with limited data:- Provides little performance gain
- Increases overfitting risk
- Can hurt generalization
Example: Unfreezing an Additional Layer
# Unfreeze layer3
for name, param in model.layer3.named_parameters():
param.requires_grad = True
Learning Rate Strategy
Stage 2 typically uses:- A lower learning rate
- Or a scheduler such as
CosineAnnealingLR
Why Two-Stage Fine-Tuning Improves Validation Accuracy
From an Optimization Perspective
Stage 1 quickly moves the model into a good region of the loss landscape. Stage 2 performs smaller, more precise adjustments that improve generalization rather than memorization.From a Generalization Perspective
This approach:- Preserves low-level visual knowledge
- Encourages smoother decision boundaries
- Reduces over-confident predictions
Typical Gains
For ResNet-18 on small to medium datasets:- ~1–3% improvement in validation accuracy
- More stable results across runs
- Better resistance to overfitting
Key Takeaways
- Two-stage fine-tuning emphasizes control and stability
- Train task-specific layers first, then refine mid-level features
- Lower layers are usually best left frozen for limited data
- ResNet-18 benefits significantly from this structured approach
Any comments? Feel free to participate below in the Facebook comment section.