How a MixUp Schedule Works
I wrote an app to classify an object using transfer learning, and the model was trained on CIFAR-10 dataset, all by myself.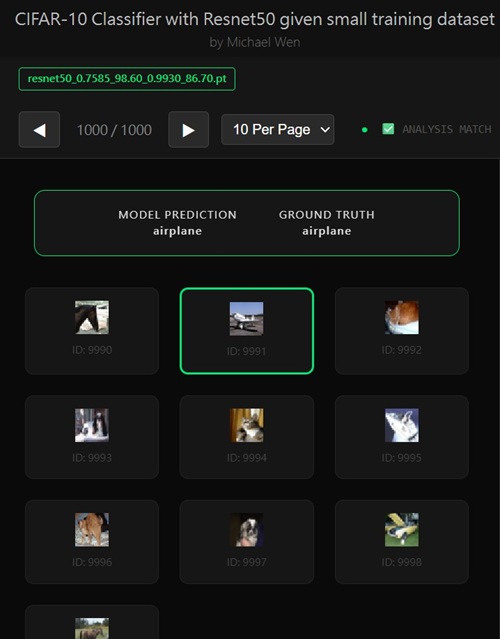
How a MixUp Schedule Works (and Why It Can Improve Validation Accuracy)
MixUp is not just a binary on/off data augmentation. In practice, its strength over time matters a lot. A MixUp schedule controls when and how strongly MixUp is applied during training. This section explains:- What a MixUp schedule is
- The math behind it
- Why scheduling helps validation accuracy
- Concrete examples and sample code
Recap: What MixUp Does (One Line)
MixUp creates a new training sample by linearly combining two samples:x̃ = λx₁ + (1 − λ)x₂ ỹ = λy₁ + (1 − λ)y₂where λ is sampled from a Beta distribution.
What Is a MixUp Schedule?
A MixUp schedule controls how the mixing coefficient λ (or its distribution) changes over training epochs. Instead of using the same MixUp strength from epoch 1 to epoch N, we vary it over time. Conceptually:- Early training: Strong MixUp (heavy regularization)
- Later training: Weaker MixUp (more task-specific learning)
Why Scheduling MixUp Makes Sense
Deep networks go through different learning phases:- Early phase: Learning general, low-level patterns
- Middle phase: Learning class structure
- Late phase: Fine-grained decision boundaries
The Math Behind MixUp Strength
λ is sampled from a Beta distribution:λ ~ Beta(α, α)Key properties:
- Small α → λ near 0 or 1 (weak MixUp)
- Large α → λ near 0.5 (strong MixUp)
Example: Constant vs Scheduled MixUp
Constant MixUp
α = 0.4 (fixed for all epochs)Problems:
- Good regularization early
- Prevents sharp decision boundaries later
- Can cap validation accuracy
Scheduled MixUp
α(epoch) = α_max × (1 − epoch / total_epochs)Behavior:
- Epoch 0 → strong MixUp
- Final epochs → near one-hot labels
Loss Function with Scheduled MixUp
The loss formula stays the same:Loss = − [ λ log(p[y₁]) + (1 − λ) log(p[y₂]) ]What changes is the distribution of λ over time. Early epochs:
- λ ≈ 0.5
- Loss encourages uncertainty and smooth boundaries
- λ → 0 or 1
- Loss resembles standard cross-entropy
Why MixUp Scheduling Improves Validation Accuracy
From a generalization perspective:- Strong MixUp reduces memorization
- Smooth targets reduce gradient variance
- Weaker MixUp later allows class separation
- Lower validation loss
- Better calibrated probabilities
- More stable decision boundaries
- Dataset is small
- Transfer learning is used
- Model easily reaches 100% train accuracy
Intuition: Decision Boundaries Over Time
- No MixUp: Sharp boundaries early → overfitting
- Always strong MixUp: Boundaries never sharpen
- Scheduled MixUp: Smooth early, sharp late
- First: broad concepts
- Later: fine distinctions
Sample Code: Core MixUp Scheduling Logic
Computing Epoch-Dependent α
def mixup_alpha(epoch, total_epochs, alpha_max=0.4):
return alpha_max * (1 - epoch / total_epochs)
Sampling λ
def sample_lambda(alpha):
if alpha <= 0:
return 1.0
return np.random.beta(alpha, alpha)
Applying MixUp
def mixup(x1, y1, x2, y2, lam):
x_mix = lam * x1 + (1 - lam) * x2
y_mix = lam * y1 + (1 - lam) * y2
return x_mix, y_mix
Training Loop (Core Idea)
for epoch in range(total_epochs):
alpha = mixup_alpha(epoch, total_epochs)
lam = sample_lambda(alpha)
x_mix, y_mix = mixup(x1, y1, x2, y2, lam)
loss = criterion(model(x_mix), y_mix)
Common Practical Variants
- Turn off MixUp completely for last K epochs
- Use cosine decay for α
- Combine MixUp schedule with label smoothing
Key Takeaways
- MixUp is a regularizer, not a free lunch
- Scheduling controls the bias–variance tradeoff
- Strong early, weak late works best in practice
- Validation accuracy improves because generalization improves
Final Insight
If your model:- Hits 100% train accuracy early
- Plateaus in validation accuracy
Any comments? Feel free to participate below in the Facebook comment section.