Strong Regularizers In Data Augmentation
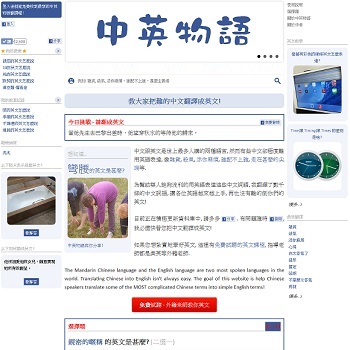
I wrote an app to classify an object using transfer learning, and the model was trained on CIFAR-10 dataset, all by myself.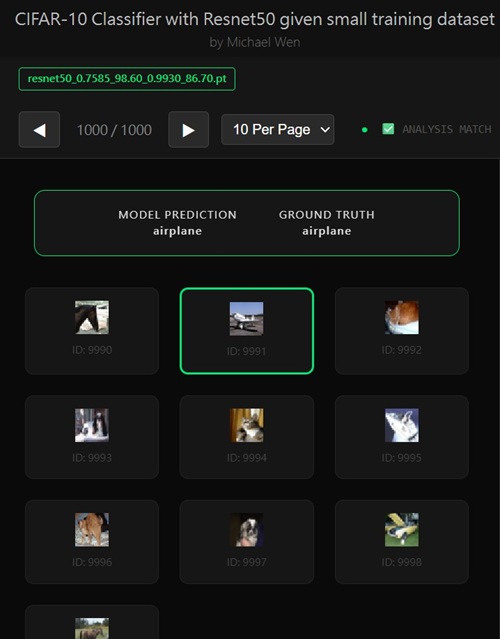
Strong Regularizers in Data Augmentation
When people talk about data augmentation, they often lump everything together: random crops, flips, color jitter, noise, erasing, MixUp, CutMix, and so on. From a learning-theory and optimization perspective, these techniques are not equal. Some are mild inductive nudges. Others are strong regularizers that fundamentally change the loss landscape. Random Erasing belongs firmly in the second category.What Do We Mean by “Strong Regularizers”?
A strong regularizer is not defined by how “random” it looks, but by how much it:- Reduces the model’s ability to memorize training samples
- Forces invariances the model would not naturally learn
- Injects bias that competes with pretrained representations
- Random Erasing (a.k.a. Cutout)
- CutMix
- MixUp (arguably the strongest)
- Heavy geometric distortions
- Large-area occlusions
Random Erasing: What It Actually Does
Random Erasing works by selecting a random rectangle in the image and replacing it with either zeros, random values, or mean pixel values. Formally, if an image is represented as: x ∈ ℝ^{H×W×C}
Random Erasing applies a mask M such that:
x̃ = x ⊙ (1 − M) + v ⊙ MWhere:
Mis a binary mask over a rectangular regionvis a constant or random value⊙is element-wise multiplication
Why Strong Regularizers Can Improve Validation Accuracy
On small datasets, CNNs often overfit by:- Locking onto texture patches
- Overusing single object parts
- Learning shortcut correlations
- Integrate information across spatial regions
- Learn more redundant representations
- Generalize when evidence is partially missing
E[L_val] − E[L_train]Especially when training accuracy is already very high.
Why Strong Regularizers Can Hurt Validation Accuracy
This is the part many tutorials skip. Strong regularizers can easily backfire in transfer learning. Why? Because pretrained backbones already encode strong priors. When Random Erasing is applied too early or too aggressively:- Features the backbone relies on are corrupted
- Gradient noise increases in unfrozen layers
- The classifier head struggles to stabilize
Var(∇L(x̃, y)) ↑If the model capacity is still high (many layers unfrozen), this extra variance leads to:
- Unstable convergence
- Higher validation loss
- No improvement — or regression — in validation accuracy
Concrete Example from Transfer Learning
Consider a ResNet-18 setup where:- Training accuracy is already ~100%
- Validation accuracy is ~85%
- Validation loss remains relatively high
- Optimization is solved
- Generalization is the bottleneck
- Training accuracy stays near 100%
- Validation accuracy stagnates or drops
- Validation loss may increase
Strong Regularizers and Training Stages
Strong regularizers work best when:- The backbone is mostly frozen
- The classifier head has already stabilized
- Model capacity is tightly controlled
- Two-stage fine-tuning
- Late-stage regularization schedules
- Lower learning rates
Key Takeaways
- Not all augmentations are equal
- Random Erasing is a strong regularizer, not a free gain
- Strong regularizers increase gradient variance
- Timing and model capacity matter more than the technique itself
- Validation drops are signals, not failures
Any comments? Feel free to participate below in the Facebook comment section.