Heavy Geometric Distortions
I wrote an app to classify an object using transfer learning, and the model was trained on CIFAR-10 dataset, all by myself.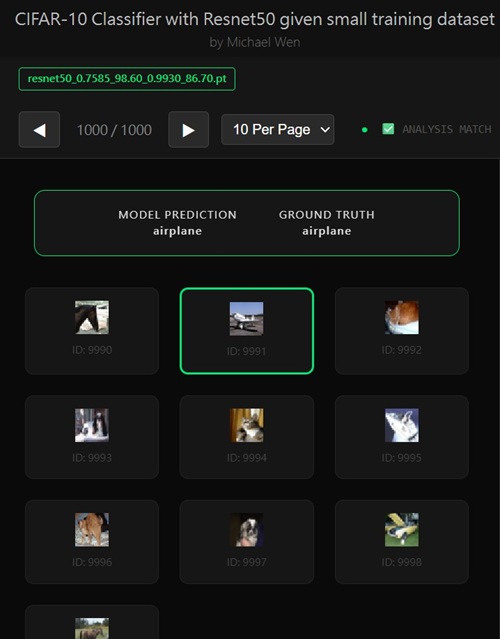
Heavy Geometric Distortions as a Regularization Strategy
Heavy geometric distortions are a class of data augmentation techniques where we intentionally warp, stretch, rotate, or otherwise deform images. The goal is to force the model to learn invariance to spatial transformations, rather than memorizing exact object shapes or positions.Common Heavy Geometric Distortions
Examples include:- Random rotation: ±30° or more
- Random scaling / zooming: making objects smaller or larger
- Random translation: shifting objects around the image
- Perspective warp: skewing the image corners
- Elastic distortions: bending objects like rubber sheets
How Geometric Distortions Affect the Model
Let’s denote the original image asx and the transformed image as x̃ = T(x), where T is a geometric transform.
The corresponding label remains the same:
ỹ = yThe cross-entropy loss is still:
L = - Σ yᵢ log pᵢ(x̃)But now the model is being trained on a wider distribution of inputs:
x̃ ~ P_augmented(x)This forces the CNN to:
- Recognize objects independent of orientation or scale
- Learn more robust feature representations
- Spread attention across spatial regions instead of overfitting to local patches
Effect on Validation Accuracy
Heavy geometric distortions can improve validation accuracy by increasing generalization. By training on warped images, the network is less likely to overfit:- Train accuracy might decrease slightly
- Val accuracy often rises
- Val loss usually decreases if distortions are reasonable
Var_augmented > Var_original
Potential Pitfalls
Heavy distortions are powerful — but too much can hurt:- Excessive rotation or scaling can make objects unrecognizable
- Small datasets are sensitive: distortions may create unrealistic samples
- Backbone pretrained on natural images may fail if spatial semantics are destroyed
- Train loss fluctuates
- Train accuracy drops
- Validation accuracy plateaus or even decreases
Interaction with Transfer Learning
In transfer learning:- Early layers capture low-level features (edges, textures)
- Mid-layers capture parts of objects
- Later layers capture full objects
- Most backbone layers are frozen
- We only fine-tune the classifier or top layers
Examples of Distortion Parameters
transforms.Compose([ transforms.RandomResizedCrop(224, scale=(0.5, 1.2)), transforms.RandomRotation(degrees=30), transforms.RandomAffine(degrees=0, translate=(0.2, 0.2), shear=15), transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2), transforms.ToTensor(), ])These transformations create new variations for every training sample, expanding the effective dataset size.
Key Takeaways
- Heavy geometric distortions are a strong regularizer
- They improve generalization when used correctly
- Excessive distortion can harm validation accuracy
- Best applied after initial stabilization of the classifier
- In transfer learning, frozen backbones are safer than full fine-tuning with heavy distortions
Any comments? Feel free to participate below in the Facebook comment section.