Two Stage Fine Tuning In Transfer Learning
I wrote an app to classify an object using transfer learning, and the model was trained on CIFAR-10 dataset, all by myself.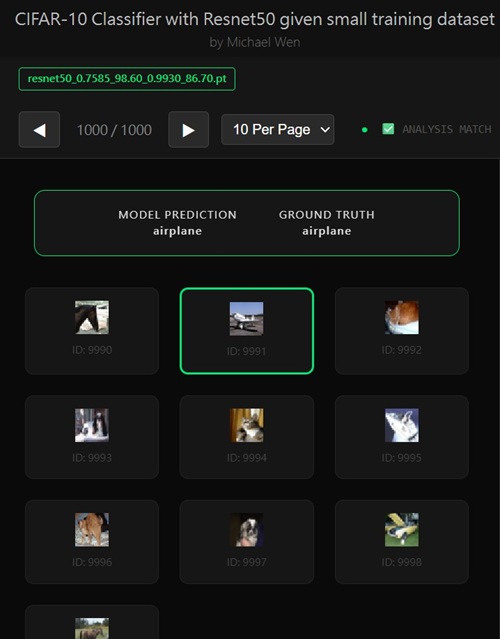
Two Stage Fine Tuning In Transfer Learning
Next, I moved on to a more structured training strategy: 2-stage fine-tuning, and I applied it consistently across all four backbones—MobileNet V2, MobileNet V3, ResNet-18, and ResNet-34.Why 2-Stage Fine-tuning Makes Sense
Next, I moved on to a more structured training strategy: 2-stage fine-tuning, and I applied it consistently across all four backbones—MobileNet V2, MobileNet V3, ResNet-18, and ResNet-34. The main reason for doing this was simple: with only 100 samples per class, fully unfreezing a pretrained network from the start is almost guaranteed to cause overfitting.The lower layers of these models already contain very general visual knowledge—edges, corners, textures, and basic shapes—learned from massive datasets. Letting those layers change too early would erase useful information and hurt generalization. A staged approach lets the model adapt slowly and safely, keeping what already works while only adjusting what really needs to change.
Stage 1: Train the Top, Freeze the Rest
In Stage 1, I froze most of the network and only unfroze the final block and the classifier head. For the ResNet models, this meant unfreezinglayer4 along with the fully connected (fc) layer.
For MobileNet V2 and V3, the idea was the same even though the internal structure is different: only the last high-level feature layers and the classifier were allowed to update. This stage is mainly about alignment. The classifier learns how to map pretrained features to CIFAR-10 classes, while the top layers slightly adjust to differences in image size, texture, and visual style between CIFAR-10 and ImageNet. Because only a small part of the network is trainable, training stays stable and overfitting is kept under control.
Stage 2: Carefully Unfreezing Deeper Layers
After Stage 1 converged and validation accuracy started to level off, I moved on to Stage 2.Here, I unfroze one additional block—
layer3 in the ResNet models. This part of the network sits in a middle zone: it’s not learning simple edges anymore, but it’s also not fully specialized for ImageNet classes.
By unfreezing it, I allowed the model to gently reshape its mid-level features, such as object parts, textures, and class-specific patterns, so they better matched CIFAR-10. Importantly, the lower layers remained frozen, which helped preserve strong general-purpose features.
Why This Strategy Worked So Well
From a technical standpoint, staged fine-tuning also made it easier to control learning rates. Newly unfrozen layers could learn faster, while earlier layers were either frozen or updated very slowly. This reduced noisy updates and helped the model converge smoothly instead of forgetting what it had already learned.Across MobileNet V2, MobileNet V3, ResNet-18, and ResNet-34, this 2-stage approach consistently performed better than unfreezing everything at once. It struck a clean balance between flexibility and restraint, which turned out to be critical when training with such a small dataset.
Any comments? Feel free to participate below in the Facebook comment section.