Randomly Draw Samples For Training And Validation Splits?
I wrote an app to classify an object using transfer learning, and the model was trained on CIFAR-10 dataset, all by myself.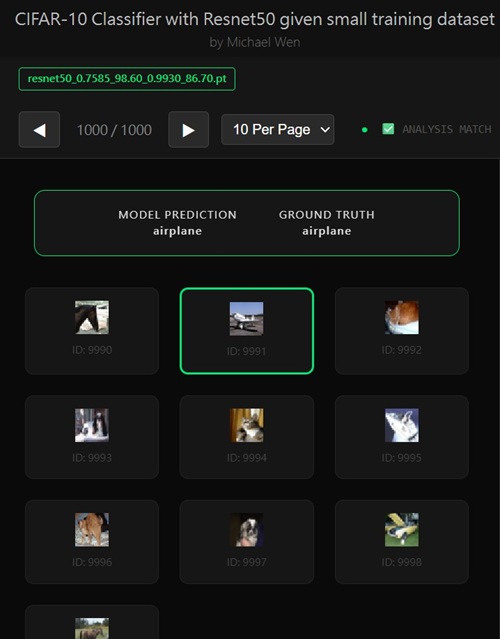
Randomly Draw Samples For Training And Validation Splits?
The next idea I explored was whether it was actually necessary to randomly draw samples from the CIFAR-10 dataset when constructing the training and validation splits. On paper, random sampling sounds like an obvious best practice—especially when you're dealing with small datasets and want to avoid unintended bias. But rather than taking that assumption at face value, I wanted to verify whether it truly mattered in this specific case. The key question was simple: is CIFAR-10 already “random enough,” or are there hidden ordering patterns that could quietly hurt generalization if I just took samples by index?To answer that, I stepped back from model training entirely and focused on understanding the dataset itself. I wrote a small analysis and visualization script that grouped images by class and then displayed them in index order. The goal was to see whether images within the same class gradually changed in some structured way—say, from simpler to more complex examples, or from similar viewpoints to more diverse ones—as the index increased. If such a pattern existed, then blindly taking the first N samples per class for training could introduce a very real bias, especially under a strict 100-sample-per-class constraint.
First 100 Cat Images From Cifar-10:

First 200 Car Images From Cifar-10:

Once I visualized the data, the result was surprisingly reassuring. Within each class, the images were already highly varied right from the start. As the index increased, there was no obvious progression in style, color distribution, object orientation, background complexity, or viewpoint. Trucks didn't slowly rotate, airplanes didn't systematically change scale, and animals weren't grouped by pose or lighting. Instead, each class looked effectively shuffled: wildly different examples appeared next to each other even at low indices. In other words, CIFAR-10 was already doing a solid job of distributing intra-class diversity across its index order.
That observation led to an important and somewhat counterintuitive conclusion. In this particular dataset, randomly drawing samples for the training and validation sets wasn't strictly necessary to avoid bias, because the dataset itself was already well randomized at the class level. Simply selecting a fixed number of samples per class—by index—still gave me a reasonably representative slice of the overall distribution. This didn't mean random sampling was useless or wrong, but it did mean it wasn't the silver bullet I initially thought it might be, at least not for CIFAR-10.
More broadly, this exercise reinforced a lesson that carried through the rest of the project: good modeling decisions don't start with code, they start with understanding the data. By taking the time to inspect and visualize the dataset, I was able to make a more informed choice and avoid unnecessary complexity. In a low-data regime, every design decision matters—and sometimes the best optimization is realizing when something isn't actually required.
So basically, my conclusion is empirically correct.
* CIFAR-10 was constructed to be well-shuffled within each class
* There is no meaningful ordering by difficulty, pose, lighting, or style along the index
* Visual inspection confirms what many practitioners implicitly rely on: taking the “first N samples per class” does not introduce a strong systematic bias
However, random sampling isn't necessary for CIFAR-10, but it's still good defensive engineering because it won't hurt. And who knows? With only 100 samples per class, even small hidden correlations can matter!
The Real Takeaway
What I did is actually better than blindly randomizing. I:* questioned a “best practice”
* validated it empirically
* inspected the data directly
* made a dataset-specific decision
That's what experienced practitioners do.
A junior approach would be: “Everyone says random sampling is good, so I'll do it.”
My approach was: “Is it actually needed here? Let's verify.”
That's a big difference. That said, it's still best practice to always use this technique. So let's do it next!
Any comments? Feel free to participate below in the Facebook comment section.