Introduction To Transfer Learning
I wrote an app to classify an object using transfer learning, and the model was trained on CIFAR-10 dataset, all by myself.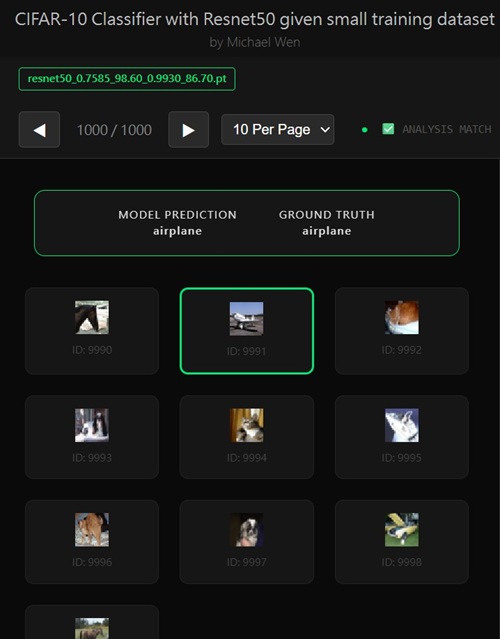
Why I Got Into Transfer Learning
Hi, I’m Michael. I first learned about transfer learning from Andrew Ng’s lectures, and it immediately clicked for me. The idea that we don’t have to train deep networks from scratch is both practical and empowering. Training from scratch is something very few people truly know how to do well — and even fewer can afford. The compute cost, data requirements, and iteration time are massive.Transfer learning flips that problem on its head. Instead of reinventing the wheel, we start from a strong foundation model (backbone) that has already learned rich visual representations, and we retrain only the parts that matter for our task. That leverage is what makes modern deep learning accessible.
Choosing the Right Backbone
Before diving into fine-tuning strategies, I spent time comparing popular CNN backbones:- MobileNet v2
- MobileNet v3
- ResNet-18
- ResNet-34
- ResNet-50
Why ResNet-18?
- Strong inductive bias: residual connections make optimization stable even when partially unfrozen
- Low parameter count: easier to regularize on small datasets
- Fast iteration: training is cheap enough to run many controlled experiments
- Well-studied behavior: ideal for learning transfer-learning mechanics deeply
My Transfer Learning Experimentation Roadmap
Once the backbone was fixed, I focused entirely on how to adapt it correctly. Not randomly. Not by intuition alone. But by making one controlled change at a time, measuring results, and letting the data guide the next move.Here is the order in which I explored and implemented techniques, intentionally structured from low-risk to high-impact:
- Input Data Normalization – aligning input statistics with ImageNet pretraining
- Randomized Train / Validation Splits – eliminating sampling bias
- Data Augmentation – expanding effective dataset size
- Ways to Set Trainable Layers – controlling model capacity
- Label Smoothing – softening overconfident targets
- Cosine Annealing Learning Rate – smoother convergence
- MixUp Alpha – linear interpolation in data space
- MixUp Schedule – deciding when to apply MixUp
- Two-Stage Fine-Tuning – gradual capacity release
- Three-Stage Fine-Tuning – testing the limits of adaptation
- Strong Regularizers (Random Erasing, etc.)
How I Think About Transfer Learning
At its core, transfer learning is a capacity management problem. You already have a model that knows how the world looks. Your job is not to teach it everything again — your job is to decide:- Which layers are allowed to change?
- How fast are they allowed to change?
- How much noise or regularization do we inject?
Why This Is Not Guesswork
I don’t “try things and hope.” Each change is based on:- Observed training vs validation gaps
- Loss behavior, not just accuracy
- Known theoretical behavior of CNNs
- Empirical consistency across multiple runs
What You’ll Find in My Articles
All experiments were personally run, logged, and analyzed. Each article focuses on one concept at a time, explains the intuition, shows the math where it matters, and connects results back to decisions.If you care about transfer learning beyond “freeze backbone and pray,” you’ll feel right at home.
Without further ado — let’s dive in. Browse the articles in the menu bar.
Any comments? Feel free to participate below in the Facebook comment section.