Michael's Document Search Engine
 Amazon
In a distributed system course I took we decided to do a project with Google API.
Amazon
In a distributed system course I took we decided to do a project with Google API.
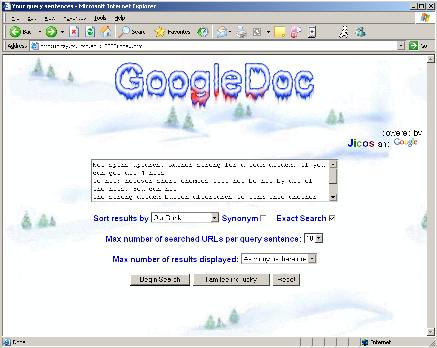
Our vision to create a document search engine so that the user can find a document on the Internet that has a high degree of similarity to the given document. We call this system 'GoogleDoc'.
Possible applications include checking for
plagiarism in the academia, learning more about a big topic, and checking to see
whether an idea is already taken.
We use JICOS to do distributed and parallel
computing so that computation of results of a query can be returned in the
shortest amount of time possible.
One thing worth noting is that Google's rank is based on hundreds of factors, many of which are related to the popularity of the web page. Therefore the highest ranked web page does not even have to contain similarity the query document. The goal of a document search engine is that if there exists such a similar document on the Web, we should find it and it should be ranked at the very top.
[2012/12/25] Later Google did come out with a service called Google Doc which was renamed Google Drive later.
Therefore we came up with our own ranking mechanism that assigns each
returned URL a score based on purely the similarity and relevancy. The user can
choose to display the results according to Google rank, Our rank, or
alphabetical order.
Also Google API imposes several constraints such as the number of queries one can make and so on. Since our underlying search system relies on Google API completely, we have no control over that.
Our system is written in 100% pure Java. We use JSP technology so that our system can be made accessible to anyone who has an Internet-enabled browser. Here are a couple of snapshots of GoogleDoc's user interface and results' display:
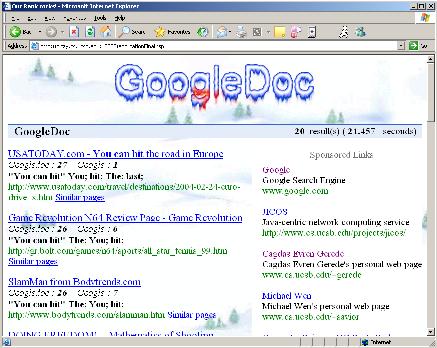
As you can see Ice and Fire coexist in 'GoogleDoc', meaning that it is able to perform well under situations of both extremes.